


La entrada de hoy será para publicar que sigo avanzando en mis estudios de programación. El último modulo que he acabado me permite comunicarme con el SO mediante Python y ejecutar scripts de control con BASH (GNU/Linux)
Ha sido un modulo bastante complicado, ya que he tocado aspectos como:
- Instalación de Python en los distintos SO.
- Manejo de archivos locales y remotos con Python.
- Expresiones regulares (un tema bastante complejo).
- Manejo de datos (CSV) y procesos.
- Técnicas de test unitarios para los programas creados.
- BASH scripting.
Y cómo no, hubo un proyecto final, que me costó bastante. El cual detallaré más adelante.
Viniendo de un curso básico de Python reforzado por otras clases complementarias. Este módulo en concreto, pisó el acelerador en cuestión de código. Había que tener los conceptos muy claros en especial de la creación de las funciones. Al igual que usar parámetros.
Si fallaba todo esto, uno se puede sentir sobrepasado y confuso.
Afortunadamente, en este curso impartido por Google. Es bastante ameno y te animan constantemente a repasar, investigar por tu cuenta y volver a revisar los temas anteriores si te hace falta. Lo cual, tuve que hacer unas cuantas veces para poder asentar conocimientos.

En todos los módulos, en el final, hay un proyecto el cual se aplica todo lo aprendido. En este caso, crear un script para encontrar errores específicos en los archivos de registro, planificar e investigar como resolver el problema y por último, implementar su solución.
Esto lo haremos con:
- Usar expresiones regulares para analizar archivos.
- Añadir y modificar valores de un diccionario.
- Escribir en un archivo con formato CSV.
- Mover los archivos al directorio apropiado para usar un conversor CSV -> HTML
Antes de empezar quisiera aclarar que el laboratorio de Google proporciona un archivo que hace la conversión de CSV a HTML, dejándonos a nosotros la tarea de operar con el archivo en búsqueda de la información requierida. Trataré sobre ese archivo cuando tenga más dominado Pandas y/u otra librería que trabaje con tablas.
Así que más o menos lo resolví así:
#!/usr/bin/env python3
import re
import sys
import operator
import csv
# Estas importaciones nos permitirá manejarnos con las expresiones regulares, archivos CSV, comandos de sistema, trabajar con diccionarios
users={}
errors={}
# Creamos dos diccionarios vacíos que rellenaremos con los archivos gracias a iterarlos.
varFile = open ("syslog.log") #Abrimos el archivo a trabajar con el
for line in varFile: # Iteramos sobre el.
line = line.strip() # Separamos los valores
usrname = (re.search(r"\((.*)\)",line)).group(1) # Y buscamos coincidencias
msg = (re.search(r"(ERROR|INFO)",line)).group(1) # Lo mismo, pero con las palabras "error" o "info"
if (usrname not in users): # Si no aparece coincidencia en el diccionario "users" no sumeramos errores pero si, n de usuarios
user_count = {'INFO': 0, 'ERROR': 0}
users[usrname] = user_count
users[usrname][msg]+=1
if msg=="ERROR": # Al revés en que el anterior, aquí si contaremos errores.
err=(re.search(r"ERROR (.*) ",line)).group(1)
if (err not in errors):
errors[err]=0
errors[err]+=1
varFile.close()
users2=[]
errors2=[]
# Creamos 2 listas.
for key in sorted(users.keys()):
users2.append([key,users[key]["INFO"],users[key]["ERROR"]]) # Itereamos por el diccionario "users" y añadimos aquellos con ERROR e INFO
for key, value in sorted(errors.items(), key=lambda item: item[1],reverse=True):
errors2.append([key, value]) # Aquí añadiremos solo los errores
# Insertamos los valores en las listas.
users2.insert(0,["Username","INFO","ERROR"])
errors2.insert(0,["Error","Count"])
# Creamos dos archivos csv
file_errors=open("error_message.csv","w")
file_users=open("user_statistics.csv","w")
# Escribimos en los archivos CSV con columnas.
writer1=csv.writer(file_erros)
writer2=csv.writer(file_users)
writer1.writerows(errors2)
writer2.writerows(users2)
# Y cerramos archivos.
file_errors.close()
file_users.close()
Una vez hemos hecho el script, nos queda guardarlo en la ruta donde se guarden los archivos de logs, darle persmisos de ejecución a traves de «chmod +x ./converter.py«
Al ejecutarlo se nos generará dos archivos «file_users.csv» y «file_errors.csv» los cuales serán los parámetros de nuestro ejecutable conversor csv_to_html.py Lo cual quedaría así.
user@user-$:./csv_to_html.py file_errors.csv /var/www/html/file_errors.html # Lo mismo para los usuarios user@user-$:./csv_to_html.py file_users.csv /var/www/html/file_users.html
Lo cual, cuando visualizamos los dos archivos HTML, veremos estas páginas:
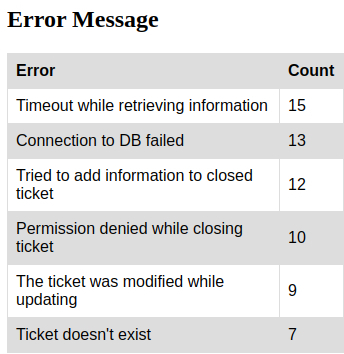
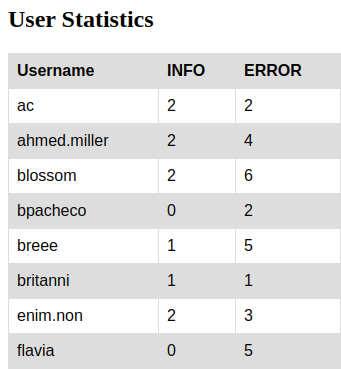
Con esta información hemos aprendido, como detectar errores, manejar la información de los usuarios, generar informes web con la información extraída de archivos de registro tipo log.
Una tarea bastante dura, ya que requerió que repasara las lecciones, consutara la documetanción asociada a las librerías importadas y fuera haciendo pequeñas pruebas de código, comprobando que este fuera funcional.
Tarea dura, pero satisfactoria y aunque me llevó bastante tiempo. Dio sus frutos.
Toca seguir, ahora me zambulliré en las metodologías Git y control de revisiones de código. Y mientras iré publicando más artículos sobre ciberseguridad, pero cada vez más enfocados hacia el sector de la industria.
Un saludo, nos vemos.